The English Lexicon Project (Balota et al., 2007) was a large-scale multicenter study to examine properties of English words. It incorporated both a lexical decision task and a word recognition task. Different groups of subjects participated in the different tasks.
2 Extracting data tables from the raw data
The raw data are available as an OSF project as Zip files for each of the tasks. These Zip files contain one data file for each participant, which has a mixture of demographic data, responses on some pre-tests, and the actual trial runs.
Parsing these data files is not fun – see this repository for some of the code used to untangle the data. (This repository is an unregistered Julia package.)
Some lessons from this:
When an identifier is described as a “unique subject id”, it probably isn’t.
In a multi-center trial, the coordinating center should assign the range of id’s for each satellite site. Failure of a satellite site to stay within its range should result in banishment to a Siberian work camp.
As with all data cleaning, the prevailing attitude should be “trust, but verify”. Just because you are told that the file is in a certain format, doesn’t mean it is. Just because you are told that the identifiers are unique doesn’t mean they are, etc.
It works best if each file has a well-defined, preferably simple, structure. These data files had two different formats mushed together.
This is the idea of “tidy data” - each file contains only one type of record along with well-defined rules of how you relate one file to another.
If one of the fields is a date, declare the only acceptable form of writing a date, preferably yyyy-mm-dd. Anyone getting creative about the format of the dates will be required to write the software to parse that form (and that is usually not an easy task).
As you make changes in a file, document them. If you look at the EnglishLexicon.jl repository you will see that it is in the form of scripts that take the original Zip files and produce the Arrow files. That way, if necessary, the changes can be undone or modified.
Remember, the data are only as useful as their provenance. If you invested a lot of time and money in gathering the data you should treat it as a valued resource and exercise great care with it.
The Arrow.jl package allows you to add metadata as key/value pairs, called a Dict (or dictionary). Use this capability. The name of the file is not a suitable location for metadata.
2.1 Trial-level data from the LDT
In the lexical decision task the study participant is shown a character string, under carefully controlled conditions, and responds according to whether they identify the string as a word or not. Two responses are recorded: whether the choice of word/non-word is correct and the time that elapsed between exposure to the string and registering a decision.
Several covariates, some relating to the subject and some relating to the target, were recorded. Initially we consider only the trial-level data.
ldttrial =dataset(:ELP_ldt_trial)
Arrow.Table with 2745952 rows, 5 columns, and schema:
:subj Int16
:seq Int16
:acc Union{Missing, Bool}
:rt Int16
:item String
with metadata given by a Base.ImmutableDict{String, String} with 3 entries:
"title" => "Trial-level data from Lexical Discrimination Task in the Engl…
"reference" => "Balota et al. (2007), The English Lexicon Project, Behavior R…
"source" => "https://osf.io/n63s2"
The two response variables are acc - the accuracy of the response - and rt, the response time in milliseconds. There is one trial-level covariate, seq, the sequence number of the trial within subj. Each subject participated in two sessions on different days, with 2000 trials recorded on the first day.
Notice the metadata with a citation and a URL for the OSF project.
We convert to a DataFrame and add a Boolean column s2 which is true for trials in the second session.
From the basic summary of ldttrial we can see that there are some questionable response times — negative values and values over 32 seconds.
Because of obvious outliers we will use the median response time, which is not strongly influenced by outliers, rather than the mean response time when summarizing by item or by subject.
Also, there are missing values of the accuracy. We should check if these are associated with particular subjects or particular items.
2.2.1 Summaries by item
To summarize by item we group the trials by item and use combine to produce the various summary statistics. As we will create similar summaries by subject, we incorporate an ‘i’ in the names of these summaries (and an ‘s’ in the name of the summaries by subject) to be able to identify the grouping used.
byitem =@chain ldttrial begingroupby(:item)@combine(:ni =length(:acc), # no. of obs:imiss =count(ismissing, :acc), # no. of missing acc:iacc =count(skipmissing(:acc)), # no. of accurate:imedianrt =median(:rt), )@transform!(:wrdlen =Int8(length(:item)),:ipropacc =:iacc /:ni )end
80962×7 DataFrame
80937 rows omitted
Row
item
ni
imiss
iacc
imedianrt
wrdlen
ipropacc
String
Int64
Int64
Int64
Float64
Int8
Float64
1
a
35
0
26
743.0
1
0.742857
2
e
35
0
19
824.0
1
0.542857
3
aah
34
0
21
770.5
3
0.617647
4
aal
34
0
32
702.5
3
0.941176
5
Aaron
33
0
31
625.0
5
0.939394
6
Aarod
33
0
23
810.0
5
0.69697
7
aback
34
0
15
710.0
5
0.441176
8
ahack
34
0
34
662.0
5
1.0
9
abacus
34
0
17
671.5
6
0.5
10
alacus
34
0
29
640.0
6
0.852941
11
abandon
34
0
32
641.0
7
0.941176
12
acandon
34
0
33
725.5
7
0.970588
13
abandoned
34
0
31
667.5
9
0.911765
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
80951
zoology
33
0
32
623.0
7
0.969697
80952
poology
33
0
32
757.0
7
0.969697
80953
zoom
35
0
34
548.0
4
0.971429
80954
zool
35
0
30
633.0
4
0.857143
80955
zooming
33
0
29
617.0
7
0.878788
80956
sooming
33
0
30
721.0
7
0.909091
80957
zooms
33
0
30
598.0
5
0.909091
80958
cooms
33
0
31
660.0
5
0.939394
80959
zucchini
34
0
29
781.5
8
0.852941
80960
hucchini
34
0
32
727.5
8
0.941176
80961
Zurich
34
0
21
731.5
6
0.617647
80962
Zurach
34
0
26
811.0
6
0.764706
It can be seen that the items occur in word/nonword pairs and the pairs are sorted alphabetically by the word in the pair (ignoring case). We can add the word/nonword status for the items as
This table shows that some of the items were never identified correctly. These are
filter(:iacc => iszero, byitem)
9×8 DataFrame
Row
item
ni
imiss
iacc
imedianrt
wrdlen
ipropacc
isword
String
Int64
Int64
Int64
Float64
Int8
Float64
Bool
1
baobab
34
0
0
616.5
6
0.0
true
2
haulage
34
0
0
708.5
7
0.0
true
3
leitmotif
35
0
0
688.0
9
0.0
true
4
miasmal
35
0
0
774.0
7
0.0
true
5
peahen
34
0
0
684.0
6
0.0
true
6
plosive
34
0
0
663.0
7
0.0
true
7
plugugly
33
0
0
709.0
8
0.0
true
8
poshest
34
0
0
740.0
7
0.0
true
9
servo
33
0
0
697.0
5
0.0
true
Notice that these are all words but somewhat obscure words such that none of the subjects exposed to the word identified it correctly.
We can incorporate characteristics like wrdlen and isword back into the original trial table with a “left join”. This operation joins two tables by values in a common column. It is called a left join because the left (or first) table takes precedence, in the sense that every row in the left table is present in the result. If there is no matching row in the second table then missing values are inserted for the columns from the right table in the result.
Notice that the wrdlen and isword variables in this table allow for missing values, because they are derived from the second argument, but there are no missing values for these variables. If there is no need to allow for missing values, there is a slight advantage in disallowing them in the element type, because the code to check for and handle missing values is not needed.
This could be done separately for each column or for the whole data frame, as in
describe(disallowmissing!(ldttrial; error=false))
8×7 DataFrame
Row
variable
mean
min
median
max
nmissing
eltype
Symbol
Union…
Any
Union…
Any
Int64
Type
1
subj
409.31
1
409.0
816
0
Int16
2
seq
1687.21
1
1687.0
3374
0
Int16
3
acc
0.85604
false
1.0
true
1370
Union{Missing, Bool}
4
rt
846.325
-16160
732.0
32061
0
Int16
5
item
Aarod
zuss
0
String
6
s2
0.407128
false
0.0
true
0
Bool
7
wrdlen
7.99835
1
8.0
21
0
Int8
8
isword
0.499995
false
0.0
true
0
Bool
Named argument “error”
The named argument error=false is required because there is one column, acc, that does incorporate missing values. If error=false were not given then the error thrown when trying to disallowmissing on the acc column would be propagated and the top-level call would fail.
A barchart of the word length counts, Figure 1, shows that the majority of the items are between 3 and 14 characters.
Code
let wlen =1:21draw(data((; wrdlen=wlen, count=counts(byitem.wrdlen, wlen))) *mapping(:wrdlen =>"Length of word", :count) *visual(BarPlot), )end
Figure 1: Barchart of word lengths in the items used in the lexical decision task.
To examine trends in accuracy by word length we plot the proportion accurate versus word-length separately for words and non-words with the area of each marker proportional to the number of observations for that combination (Figure 2).
Figure 2: Proportion of accurate trials in the LDT versus word length separately for words and non-words. The area of the marker is proportional to the number of observations represented.
The pattern in the range of word lengths with non-negligible counts (there are points in the plot down to word lengths of 1 and up to word lengths of 21 but these points are very small) is that the accuracy for words is nearly constant at about 84% and the accuracy for nonwords is slightly higher until lengths of 13, at which point it falls off a bit.
2.2.2 Summaries by subject
A summary of accuracy and median response time by subject
bysubj =@chain ldttrial begingroupby(:subj)@combine(:ns =length(:acc), # no. of obs:smiss =count(ismissing, :acc), # no. of missing acc:sacc =count(skipmissing(:acc)), # no. of accurate:smedianrt =median(:rt), )@transform!(:spropacc =:sacc /:ns)end
814×6 DataFrame
789 rows omitted
Row
subj
ns
smiss
sacc
smedianrt
spropacc
Int16
Int64
Int64
Int64
Float64
Float64
1
1
3374
0
3158
554.0
0.935981
2
2
3372
1
3031
960.0
0.898873
3
3
3372
3
3006
813.0
0.891459
4
4
3374
1
3062
619.0
0.907528
5
5
3374
0
2574
677.0
0.762893
6
6
3374
0
2927
855.0
0.867516
7
7
3374
4
2877
918.5
0.852697
8
8
3372
1
2731
1310.0
0.809905
9
9
3374
13
2669
657.0
0.791049
10
10
3374
0
2722
757.0
0.806758
11
11
3374
0
2894
632.0
0.857736
12
12
3374
4
2979
692.0
0.882928
13
13
3374
2
2980
1114.0
0.883225
⋮
⋮
⋮
⋮
⋮
⋮
⋮
803
805
3374
5
2881
534.0
0.853883
804
806
3374
1
3097
841.5
0.917902
805
807
3374
3
2994
704.0
0.887374
806
808
3374
2
2751
630.5
0.815353
807
809
3372
4
2603
627.0
0.771945
808
810
3374
1
3242
603.5
0.960877
809
811
3374
2
2861
827.0
0.847955
810
812
3372
6
3012
471.0
0.893238
811
813
3372
4
2932
823.0
0.869514
812
814
3374
1
3070
773.0
0.909899
813
815
3374
1
3024
602.0
0.896266
814
816
3374
0
2950
733.0
0.874333
shows some anomalies
describe(bysubj)
6×7 DataFrame
Row
variable
mean
min
median
max
nmissing
eltype
Symbol
Float64
Real
Float64
Real
Int64
DataType
1
subj
409.311
1
409.5
816
0
Int16
2
ns
3373.41
3370
3374.0
3374
0
Int64
3
smiss
1.68305
0
1.0
22
0
Int64
4
sacc
2886.33
1727
2928.0
3286
0
Int64
5
smedianrt
760.992
205.0
735.0
1804.0
0
Float64
6
spropacc
0.855613
0.511855
0.868031
0.973918
0
Float64
First, some subjects are accurate on only about half of their trials, which is the proportion that would be expected from random guessing. A plot of the median response time versus proportion accurate, Figure 3, shows that the subjects with lower accuracy are some of the fastest responders, further indicating that these subjects are sacrificing accuracy for speed.
Figure 3: Median response time versus proportion accurate by subject in the LDT.
As described in Balota et al. (2007), the participants performed the trials in blocks of 250 followed by a short break. During the break they were given feedback concerning accuracy and response latency in the previous block of trials. If the accuracy was less than 80% the participant was encouraged to improve their accuracy. Similarly, if the mean response latency was greater than 1000 ms, the participant was encouraged to decrease their response time. During the trials immediate feedback was given if the response was incorrect.
Nevertheless, approximately 15% of the subjects were unable to maintain 80% accuracy on their trials
count(<(0.8), bysubj.spropacc) /nrow(bysubj)
0.15233415233415235
and there is some association of faster response times with low accuracy. The majority of the subjects whose median response time is less than 500 ms. are accurate on less than 75% of their trials. Another way of characterizing the relationship is that none of the subjects with 90% accuracy or greater had a median response time less than 500 ms.
It is common in analyses of response latency in a lexical discrimination task to consider only the latencies on correct identifications and to trim outliers. In Balota et al. (2007) a two-stage outlier removal strategy was used; first removing responses less than 200 ms or greater than 3000 ms then removing responses more than three standard deviations from the participant’s mean response.
As described in Section 2.2.3 we will analyze these data on a speed scale (the inverse of response time) using only the first-stage outlier removal of response latencies less than 200 ms or greater than 3000 ms. On the speed scale the limits are 0.333 per second up to 5 per second.
To examine the effects of the fast but inaccurate responders we will fit models to the data from all the participants and to the data from the 85% of participants who maintained an overall accuracy of 80% or greater.
As we have indicated, generally the response times are analyzed for the correct identifications only. Furthermore, unrealistically large or small response times are eliminated. For this example we only use the responses between 200 and 3000 ms.
A density plot of the pruned response times, Figure 4, shows they are skewed to the right.
Code
draw(data(pruned) *mapping(:rt =>"Response time (ms.) for correct responses") * AlgebraOfGraphics.density(); figure=(; resolution=(800, 450)),)
Figure 4: Kernel density plot of the pruned response times (ms.) in the LDT.
In such cases it is common to transform the response to a scale such as the logarithm of the response time or to the speed of the response, which is the inverse of the response time.
The density of the response speed, in responses per second, is shown in Figure 5.
Figure 5: Kernel density plot of the pruned response speed in the LDT.
Figure 4 and Figure 5 indicate that it may be more reasonable to establish a lower bound of 1/3 second (333 ms) on the response latency, corresponding to an upper bound of 3 per second on the response speed. However, only about one half of one percent of the correct responses have latencies in the range of 200 ms. to 333 ms.
count( r -> !ismissing(r.acc) &&200< r.rt <333,eachrow(ldttrial),) /count(!ismissing, ldttrial.acc)
0.005867195806137328
so the exact position of the lower cut-off point on the response latencies is unlikely to be very important.
Using inline transformations vs defining new columns
If you examine the code for (fit-elpldtspeeddens?), you will see that the conversion from rt to speed is done inline rather than creating and storing a new variable in the DataFrame.
I prefer to keep the DataFrame simple with the integer variables (e.g. :rt) if possible.
I recommend using the StandardizedPredictors.jl capabilities to center numeric variables or convert to zscores.
2.2.4 Transformation of response and the form of the model
As noted in Box & Cox (1964), a transformation of the response that produces a more Gaussian distribution often will also produce a simpler model structure. For example, Figure 6 shows the smoothed relationship between word length and response time for words and non-words separately,
Code
draw(data(pruned) *mapping(:wrdlen =>"Word length",:rt =>"Response time (ms)";:color =>:isword, ) *smooth())
Figure 6: Scatterplot smooths of response time versus word length in the LDT.
and Figure 7 shows the similar relationships for speed
Figure 7: Scatterplot smooths of response speed versus word length in the LDT.
For the most part the smoother lines in Figure 7 are reasonably straight. The small amount of curvature is associated with short word lengths, say less than 4 characters, of which there are comparatively few in the study.
Figure 8 shows a “violin plot” - the empirical density of the response speed by word length separately for words and nonwords. The lines on the plot are fit by linear regression.
Figure 8: Empirical density of response speed versus word length by word/non-word status.
2.3 Models with scalar random effects
A major purpose of the English Lexicon Project is to characterize the items (words or nonwords) according to the observed accuracy of identification and to response latency, taking into account subject-to-subject variability, and to relate these to lexical characteristics of the items.
In Balota et al. (2007) the item response latency is characterized by the average response latency from the correct trials after outlier removal.
Mixed-effects models allow us greater flexibility and, we hope, precision in characterizing the items by controlling for subject-to-subject variability and for item characteristics such as word/nonword and item length.
We begin with a model that has scalar random effects for item and for subject and incorporates fixed-effects for word/nonword and for item length and for the interaction of these terms.
2.3.1 Establish the contrasts
Because there are a large number of items in the data set it is important to assign a Grouping() contrast to item (and, less importantly, to subj). For the isword factor we will use an EffectsCoding contrast with the base level as false. The non-words are assigned -1 in this contrast and the words are assigned +1. The wrdlen covariate is on its original scale but centered at 8 characters.
Thus the (Intercept) coefficient is the predicted speed of response for a typical subject and typical item (without regard to word/non-word status) of 8 characters.
The differences in the fixed-effects parameter estimates between a model fit to the full data set and one fit to the data from accurate responders only, are small.
However, the random effects for the item, while highly correlated, are not perfectly correlated.
Code
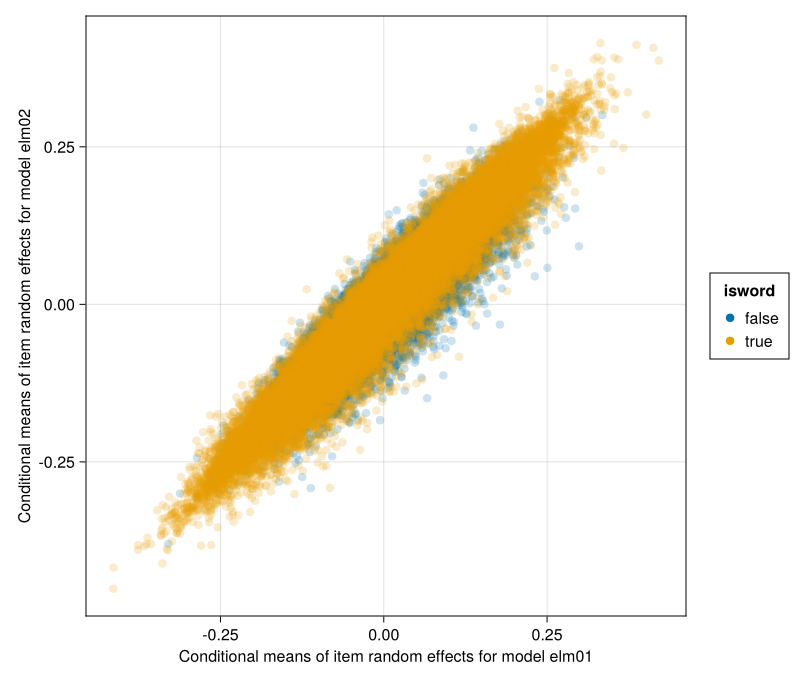
CairoMakie.activate!(; type="png")disallowmissing!(leftjoin!( byitem,leftjoin!(rename!(DataFrame(raneftables(elm01)[:item]), [:item, :elm01]),rename!(DataFrame(raneftables(elm02)[:item]), [:item, :elm02]); on=:item, ), on=:item, ),)disallowmissing!(leftjoin!( bysubj,leftjoin!(rename!(DataFrame(raneftables(elm01)[:subj]), [:subj, :elm01]),rename!(DataFrame(raneftables(elm02)[:subj]), [:subj, :elm02]); on=:subj, ), on=:subj, ); error=false,)draw(data(byitem) *mapping(:elm01 =>"Conditional means of item random effects for model elm01",:elm02 =>"Conditional means of item random effects for model elm02"; color=:isword, ) *visual(Scatter; alpha=0.2); axis=(; width=600, height=600),)
Figure 9: Conditional means of scalar random effects for item in model elm01, fit to the pruned data, versus those for model elm02, fit to the pruned data with inaccurate subjects removed.
Figure 9 is exactly of the form that would be expected in a sample from a correlated multivariate Gaussian distribution. The correlation of the two sets of conditional means is about 96%.
cor(Matrix(select(byitem, :elm01, :elm02)))
2×2 Matrix{Float64}:
1.0 0.958655
0.958655 1.0
These models take only a few seconds to fit on a modern laptop computer, which is quite remarkable given the size of the data set and the number of random effects.
The amount of time to fit more complex models will be much greater so we may want to move those fits to more powerful server computers. We can split the tasks of fitting and analyzing a model between computers by saving the optimization summary after the model fit and later creating the MixedModel object followed by restoring the optsum object.
For the simple model elm01 the estimated standard deviation of the random effects for subject is greater than that of the random effects for item, a common occurrence. A caterpillar plot, Figure 10,
Figure 10: Conditional means and 95% prediction intervals for subject random effects in elm01.
shows definite distinctions between subjects because the widths of the prediction intervals are small compared to the range of the conditional modes. Also, there is at least one outlier with a conditional mode over 1.0.
Figure 11 is the corresponding caterpillar plot for model elm02 fit to the data with inaccurate responders eliminated.
Figure 11: Conditional means and 95% prediction intervals for subject random effects in elm02.
2.4 Random effects from the simple model related to covariates
The random effects “estimates” (technically they are “conditional means”) from the simple model elm01 provide a measure of how much the item or subject differs from the population. (We use elm01 because the main difference between elm01 and elm02 are that some subjects were dropped before fitting elm02.)
For the item its length and word/non-word status have already been incorporated in the model. At this point the subjects are just being treated as a homogeneous population.
The random effects conditional means have been extracted and incorporated in the byitem and bysubj tables. Now add selected demographic and item-specific measures.
As shown in Figure 12, there does not seem to be a strong relationship between vocabulary age and speed of response by subject.
Code
draw(data(dropmissing(select(subjextended, :elm01, :vocabAge, :sex))) *mapping(:vocabAge =>"Vocabulary age (yr) of subject",:elm01 =>"Random effect in model elm01"; color=:sex, ) *visual(Scatter; alpha=0.6))
Figure 12: Random effect for subject in model elm01 versus vocabulary age
Code
draw(data(dropmissing(select(subjextended, :elm01, :univ))) *mapping(:elm01 =>"Random effect in model elm01"; color=:univ =>"University", ) * AlgebraOfGraphics.density())
Figure 13: Estimated density of random effects for subject in model elm01 by university
Code
draw(data(dropmissing(select(subjextended, :elm02, :univ))) *mapping(:elm02 =>"Random effect in model elm02 (accurate responders only)"; color=:univ =>"University", ) * AlgebraOfGraphics.density())
Figure 14: Estimated density of random effects for subject in model elm02, fit to accurate responders only, by university
Code
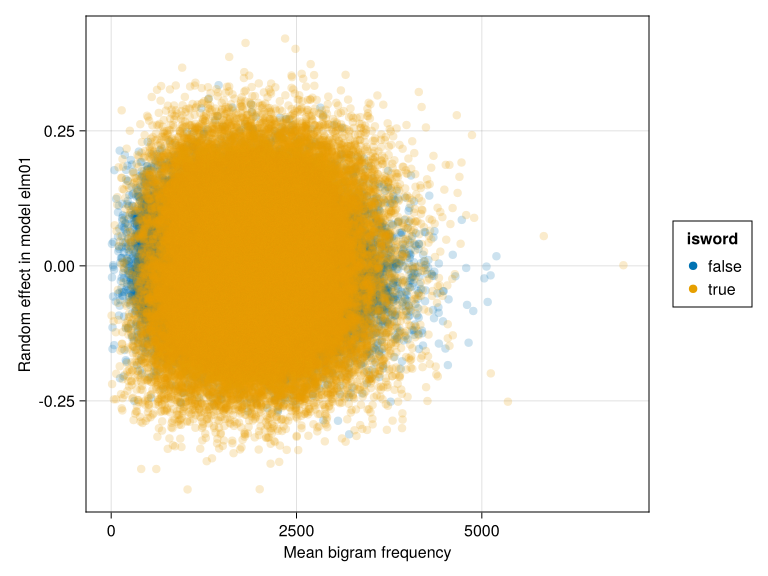
CairoMakie.activate!(; type="png")draw(data(dropmissing(select(itemextended, :elm01, :BG_Mean, :isword))) *mapping(:BG_Mean =>"Mean bigram frequency",:elm01 =>"Random effect in model elm01"; color=:isword, ) *visual(Scatter; alpha=0.2))
Figure 15: Random effect in model elm01 versus mean bigram frequency, by word/nonword status
Balota, D. A., Yap, M. J., Hutchison, K. A., Cortese, M. J., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson, G. B., & Treiman, R. (2007). The english lexicon project. Behavior Research Methods, 39(3), 445–459. https://doi.org/10.3758/bf03193014
Box, G. E. P., & Cox, D. R. (1964). An analysis of transformations. Journal of the Royal Statistical Society: Series B (Methodological), 26(2), 211–243. https://doi.org/10.1111/j.2517-6161.1964.tb00553.x